隨著深度學習模型的應用日益普及,如何有效地在資源受限的設備上運行這些模型成為了一個重要的課題。ONNX(Open Neural Network Exchange)作為一種開源的神經網絡模型交換格式,逐漸被廣泛採用,其標準化的格式使得各類深度學習框架能夠互相兼容與共享。然而,儘管 ONNX Runtime 提供了一個相對簡便的方法來部署 ONNX 模型,其體積和運行時依賴性可能對某些運算資源有限的硬體系統造成挑戰。
針對這一問題,ONNX MLIR(Multi-Level Intermediate Representation)為優化 ONNX 模型提供了一個全新的解決方案。ONNX MLIR 是基於 MLIR 編譯器基礎架構的一個開源工具,它可以將 ONNX 模型轉換為更高效的編譯碼,進而減少運行時的資源佔用,尤其適合嵌入式系統或其他受限環境。這種技術提供了一種靜態編譯方式,以去除不必要的運行時開銷,實現更優化的執行效率。
ONNX(Open Neural Network Exchange)於 2017 年由微軟和 Facebook 共同提出,目的是為了讓不同深度學習框架之間能夠無縫對接和模型共享。ONNX 提供了一個標準化的模型交換格式,使得開發者可以在 PyTorch、TensorFlow 等框架之間自由轉換模型,從而提升開發效率並加速創新。
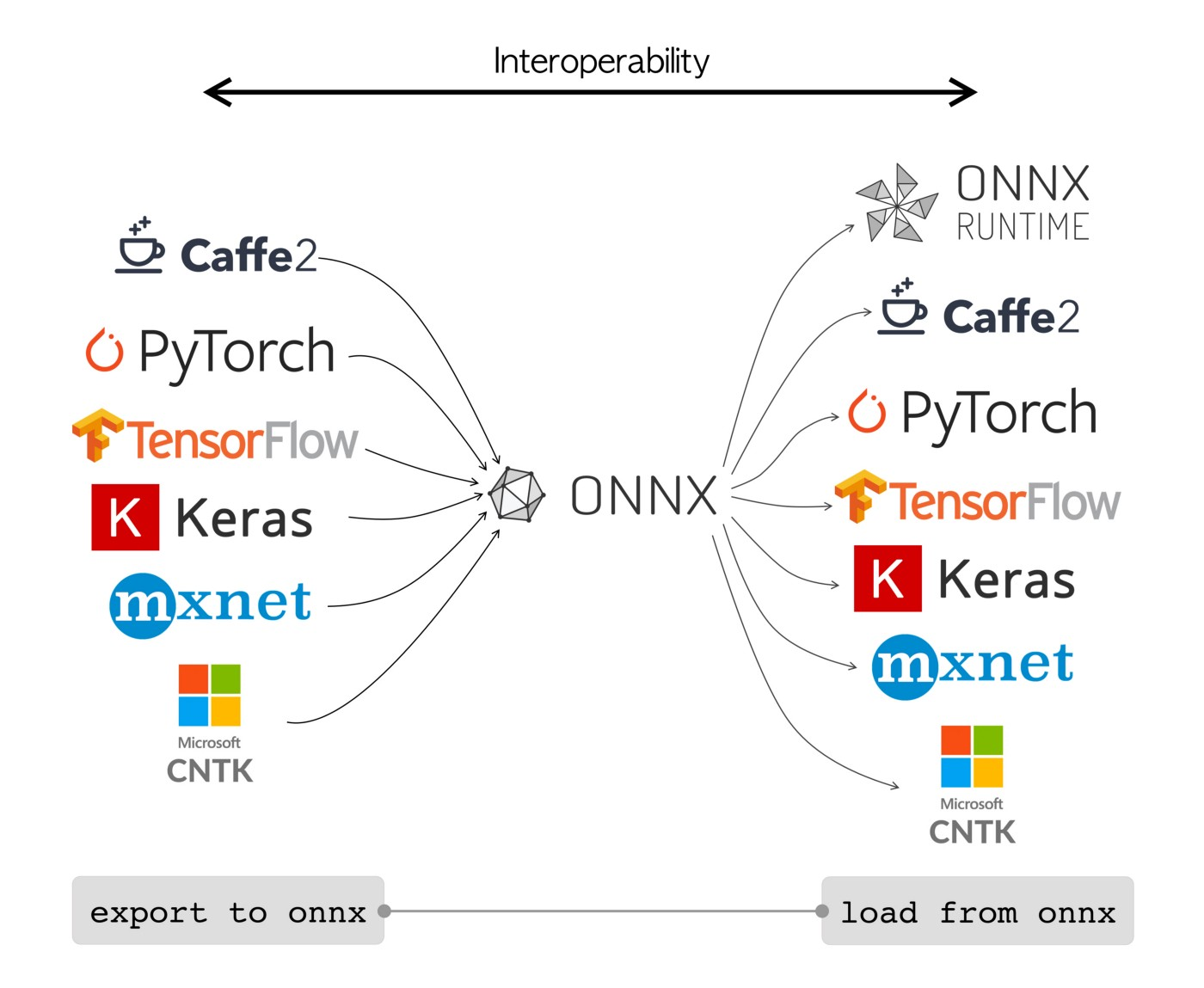
ONNX 的架構基於中間表示,允許模型的操作符和數據結構得以標準化描述,這使得各種深度學習工具和硬體加速器能夠更加便捷地集成並支援 ONNX 模型。這種標準化的特性極大地促進了生態系統的互操作性,使得開發者能夠更高效地開發、測試和部署深度學習模型。
目前深度學習領域的IR數量眾多,很難有一個IR可以統一其它的IR,這種百花齊放的局面就造成了一些困境。因此針對種種的問題,MLIR 被提出。MLIR(Multi-Level Intermediate Representation)由 Google 於 2019 年推出,其目的是為了解決現代深度學習編譯器和計算圖框架中的複雜性問題。所以我們可以說没有 TensorFlow 就没有 MLIR。MLIR 提供了一個統一的基礎架構來支援多層次的中間表示,使得不同層次的優化和轉換能夠更加靈活地進行。

圖源:Compiler Construction for Hardware Acceleration: Challenges and Opportunities
MLIR 能夠支援從高層次運算表示(例如深度學習模型)到低層次硬體特定指令碼的轉換,這種多層次的表示能力使得編譯器優化更加高效且可擴展,尤其適合於深度學習模型的優化。
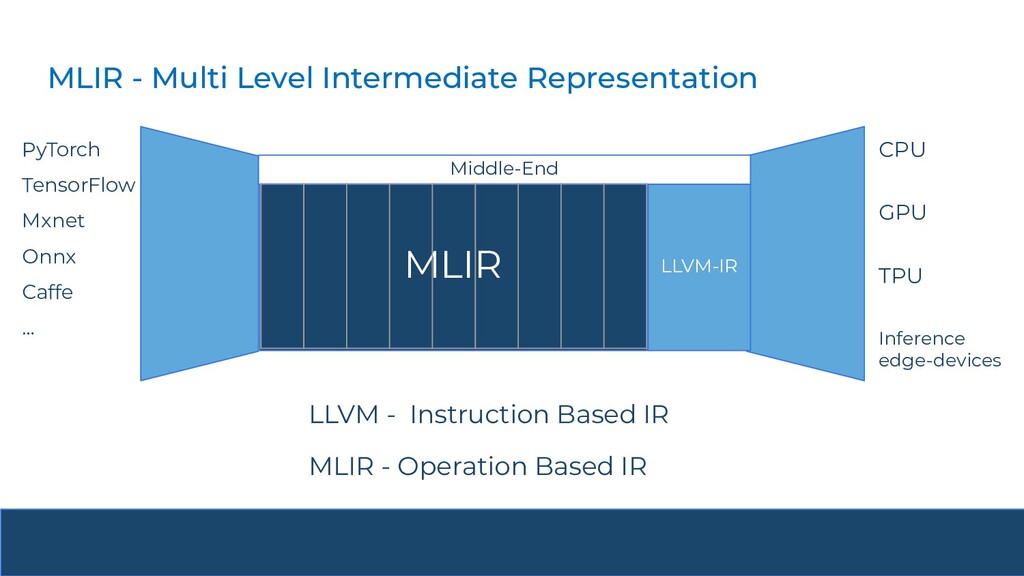
圖源:The MLIR Framework: A Brief Introduction to Deep Learning Compilers
MLIR 只是個編譯器框架,本身並沒有什麼完整功能。所以可以參考一些基於 MLIR 做的開源專案。
- onnx-mlir:連接 ONNX 與 MLIR 生態
- torch-mlir:連接 PyTorch 與 MLIR 生態
- tfrt:TensorFlow 元件,TensorFlow 新的 runtime
在了解 MLIR 之前,有必要先介紹一下 LLVM。LLVM(Low Level Virtual Machine)是一個為編譯器設計的開源項目,它提供了一個模組化和可重用的編譯器技術基礎架構。LLVM 的核心是其中間表示(IR),它可以通過多個優化 pass 進行轉換,最終生成高效的目標代碼。LLVM 主要用於傳統編譯器的優化和代碼生成,並且支援多種語言和硬體架構。

MLIR 比較適合和 LLVM 做比較,而不是 TVM 等深度學習編譯器,因為 LLVM 和 MLIR 的許多概念比較相似。如果了解 LLVM,那麼學習 MLIR 會更加容易。簡單來說 MLIR 與 LLVM 類似,是一個開源的編譯器框架。有了這些工具,我們可以更高效地建立出具備 可重用性 和 可擴展性 的編譯器,以應對現代技術環境中的多樣化挑戰。其主要目標包括:
- 處理軟硬體多樣性造成的碎片化問題
- 當今市場充斥著各種軟體選項和硬體架構,導致開發、生態系統的碎片化。這不僅使效能優化與技術採用變得困難,也阻礙了從終端設備到雲端的擴展能力。
- MLIR 提供了統一的架構,協助開發者減少碎片化對生產力和效能的影響,並促進軟硬體設計與部署的便利性。
- 異質計算的出現(Heterogeneous Computing)
- 背景:隨著摩爾定律逐漸失效,傳統通用處理器(CPU)已無法滿足現代高效能計算需求。尤其是在 AI、機器學習等應用場景中,對計算能力的需求呈爆炸性增長。
- 異質計算的特性:異質計算是一種將不同類型計算單元(如 GPU、ASIC、FPGA 等)結合的技術,透過讓「最適合的硬體處理最適合的任務」,在性能、成本與功耗之間取得平衡。
- 重要性:為了充分發揮異質計算的潛力,MLIR 幫助編譯器生成與最佳化對應的程式碼,支援多種指令集架構,並提升異構系統的效率。
MLIR 的執行過程和 LLVM 相似,都是將中間表示(IR)通過由多個 pass 組成的編譯管道進行處理,最終生成最優化的中間表示或目標代碼。不同的是,MLIR 的中間表示可以是不同方言(dialect)的,這構成了 Multi-Level 的效果。這種設計使得 MLIR 能夠靈活地支援不同的應用場景,從高層次的深度學習模型表示到低層次的硬體優化都能涵蓋,這也使 MLIR 在深度學習領域中的應用更加廣泛。
ONNX MLIR 是基於 MLIR 的一個專門工具,它將 ONNX 模型轉換為高效的編譯碼,進而減少運行時對資源的依賴。通過靜態編譯的方式,ONNX MLIR 可以去除不必要的運行時開銷,這使得模型在嵌入式系統等資源受限環境中能夠高效運行。
ONNX MLIR 的一個重要特點是它利用 MLIR 的靈活多層次表示能力,使得模型可以針對目標硬體進行更深度的優化,例如通過降低浮點精度(如 FP16、INT8 量化)來提升計算效率和降低資源佔用。
本文將首先介紹 ONNX 與 MLIR 各自的基礎概念,進而探討 ONNX MLIR 如何利用 MLIR 的多層次編譯優勢,提升深度學習模型在特定硬體上的運行效率。雖然 ONNX Runtime 在許多應用場景下已經足夠優秀,但對於需要極致性能優化或運算資源嚴重受限的場合,ONNX MLIR 無疑是一個值得考量的方案。
在後續文章中,我們將深入探討如何安裝與實作 ONNX MLIR,手把手教學如何將深度學習模型轉換並優化,讓讀者能夠實際體驗這項技術的威力。